
5 月 23 日,VerizonBusiness 《2022 数据泄露调查报告(DBIR)》显示,2022 年的勒索事件不仅没有减少,反而增幅超过过去五年的总和。2022 年上半年,就已发生多起影响或损失重大的勒索事件。
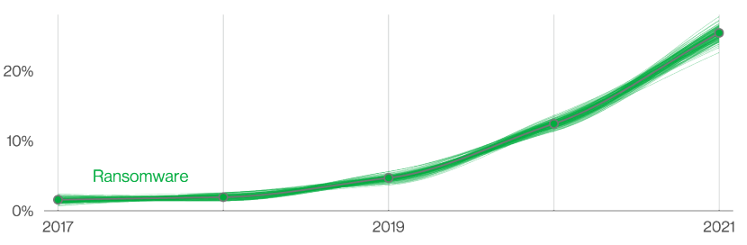
图片来源:《2022 数据泄露调查报告(DBIR)》
1 月 5 日,美国新墨西哥州伯纳利洛县遭勒索软件攻击。
3 月 1 日,丰田汽车供应商遭勒索攻击,14 家本土工厂暂时关闭。
3 月 21 日,征信巨头 TransUnion 数据泄露,对 90% 南非人造成影响。
4 月 22 日,里约财政系统遭勒索攻击,420 GB 数据被盗。
5 月 13 日,勒索攻击致使美国老牌高校林肯学院倒闭。
6 月 25 日,美国出版业巨头 Macmillan 遭勒索软件攻击后关闭系统。
面对恶意攻击,除了需要不断提升的安全策略,数据的容灾备份也是不可缺少的。
本篇目录
行业现状
现状一:行业面临的问题
灾备是一个非常古老的话题,那么目前行业面临着哪些问题呢?
1、建设力度较低
目前国内在灾备的建设力度,出现了“两低一高”的局面。
- 数据灾备投入较低
- 我国信息基础设施投资中灾备占比 2%,美国和欧洲分别为 6% 和 5%。
- 灾备覆盖率较低
- 我国大中型企业综合灾备覆盖率仅为 3%,美国和欧洲分别为 87% 和 83%。
- 业务停机损失较高
- 我国大中型企业因为停机造成的损失平均达到 78 万美元,美国为 42 万美元。
2、政府法规要求相继完善
政府相继出台了一些政策法规,在用户数据和平台基础设施层面对企业进行保护。比如:2019 年发布的条例《等级保护 2.0》、2021 年逐渐加码的关于《关键信息基础设施的保护条例》以及《数据安全法》等,都对企业提出了更高的要求。
3、社会影响驱使
在社会影响上,无论是面向个人业务还是企业服务,服务中断造成的社会影响力也在日益加深。
基于以上三点,使得企业更加重视关键信息的保护。另外,每一次针对于数据侧的解决方案,方案更新都伴随着计算平台的更新而出现。
现状二:信息化、数字化底座的新变革
· Kubernetes 大行其道
2 月 10 日,CNCF 发布《 2021 云原生调查报告》。这项已经进行了 6 年的调查显示:Kubernetes 的使用率持续增长,达到了有史以来的最高水平,90% 的组织在使用或评估这项技术。

图片来源:https://www.cncf.io/reports/cncf-annual-survey-2021/
· Kubernetes 等带来新的安全挑战
Kubernetes 大行其道趋势之下,如何保护 Kubernetes 的应用数据?逐渐成为用户使用 Kubernetes 和上云的挑战之一。
以容器、微服务、Kubernetes、DevOps 为代表的云原生技术引领着企业IT技术、架构的下一场革命,特别是在为系统的安全带来新的挑战。
根据调查显示:安全和存储两个领域,在使用、部署容器的挑战中分别列第三和第四。
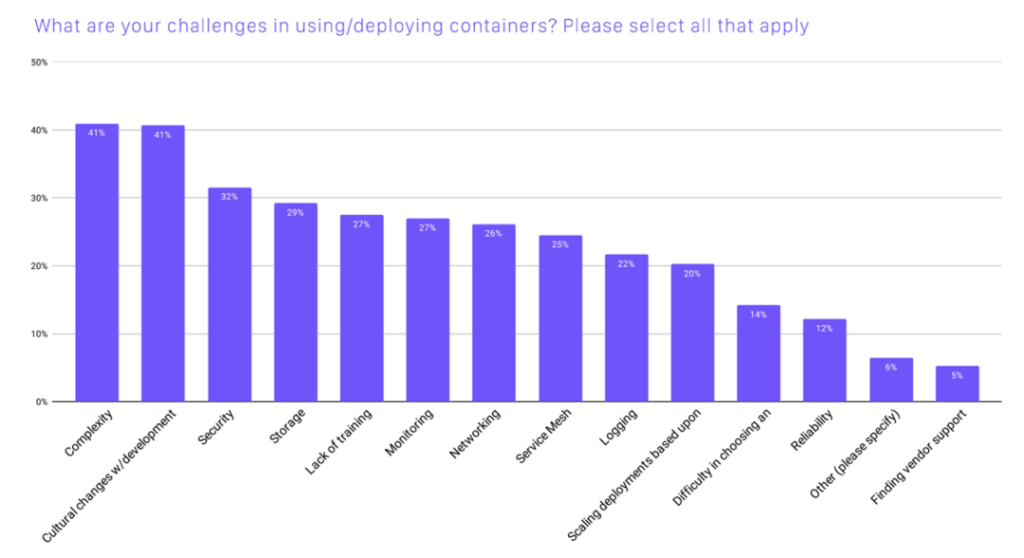
图片来源:《2020 年 CNCF 云原生调研报告》
现状三:常见的解决方案及不足
目前行业内有两种常见的数据保护方案:基于虚拟机、基于 ETCD。
方案1:基于虚拟机
该类方案主要是通过虚拟机软件(例:VMware/ KVM 等)提供的快照和备份接口直接备份虚拟机,从而备份虚拟机内的应用和数据库。
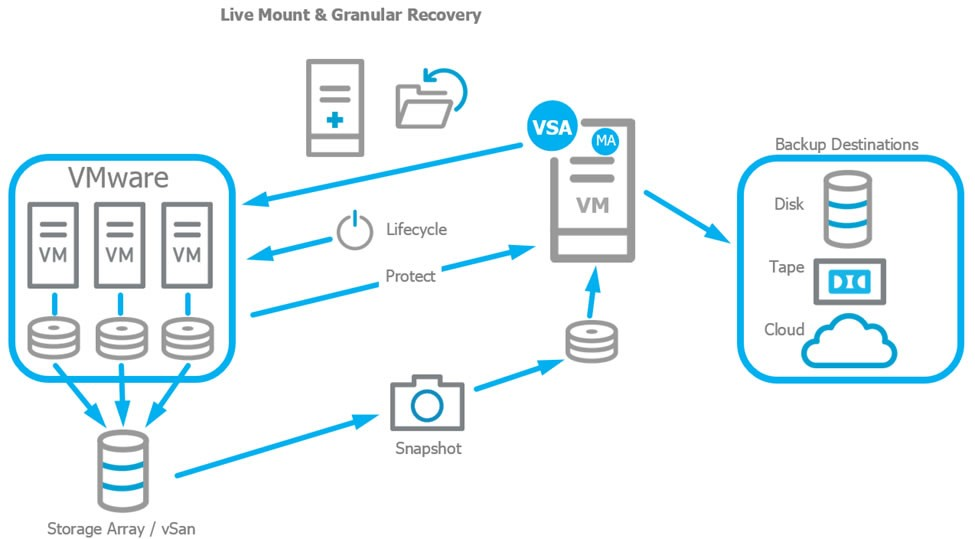
该类方案更像是保护整个机器,因此不适用于 Kubernetes 环境下动态部署、灵活扩展的容器应用。
方案2:基于 Kubernetes ETCD
ETCD 是 Kubernetes 存储集群状态和配置的数据库,可以称为集群的“大脑”。该方案可在集群发生安全事故后,通过恢复已备份的 ETCD 数据库来恢复整个集群。
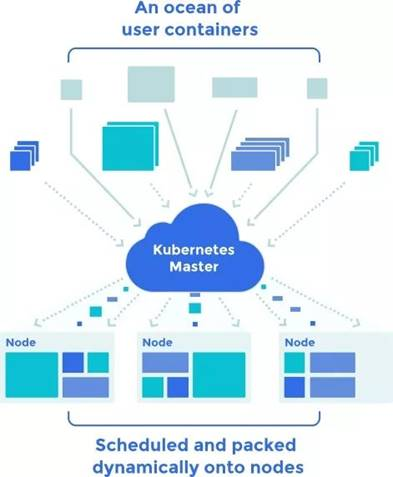
图片来源:https://s3.cn-north-1.amazonaws.com.cn/
该方案仍存在的一些不足:
- 仅对集群的资源进行整体备份或恢复,无法针对单个应用或配置。
- 仅在本集群中恢复,无法跨云或跨集群环境。
- 无法备份恢复挂载持久卷(PVC)的有状态应用(例:数据库)。
鉴于以上两种方案,可以总结为以下痛点:
- 缺少针对 Kubernetes 的数据保护方案。
- 云厂商的锁定。
- 开源技术门槛高。
- 部署维护复杂。
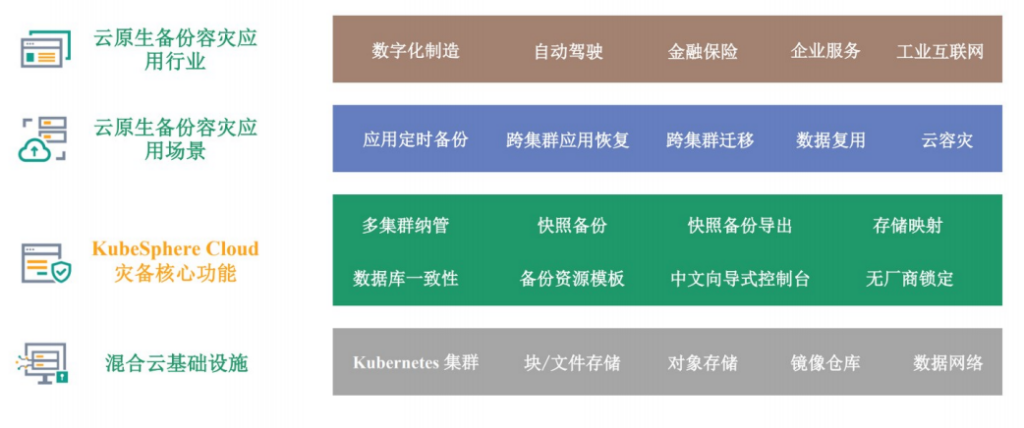
云原生数据保护的技术特征及适用场景
从以上三个行业现状看得出,针对 Kubernetes 架构的数据备份方案(云原生数据保护)需要具备以下三个特征:
特征1:以应用为中心
区别于传统备份技术(直接备份整个机器),云原生数据保护更加聚焦以应用为中心的备份。所以说数据保护的对象应该是一个应用,而不是机器!保护方式应该更细粒度且端到端,更便捷的管理,能屏蔽底层基础设施的异构性与复杂性。
特征2:全新的开发者生态
因为有了 Kubernetes 这层抽象之后,需要结合 Kubernetes 的一些特性,屏蔽底层技术架构的异构性和复杂性,来实现应用数据的迁移或备份上的一致。现在面对全新的开发者生态,需要向 DevOps 或微服务最佳实践去深度结合,来快速交付应用,完成自助式的备份。
特征3:面向多云的环境
现在用户的基础设施,并不完全都在用户本地,很多都是在公有云,像青云 QKE 容器引擎上面。而云厂商计算资源的价格变化是比较大的,我们可以根据前者不断的变化,来相应地选择所需要的底层技术资源,去实现应用的迁移,实现降本增效。
云原生数据保护可以应用在哪里呢?主要有三个场景。
场景一:数据的日常备份恢复
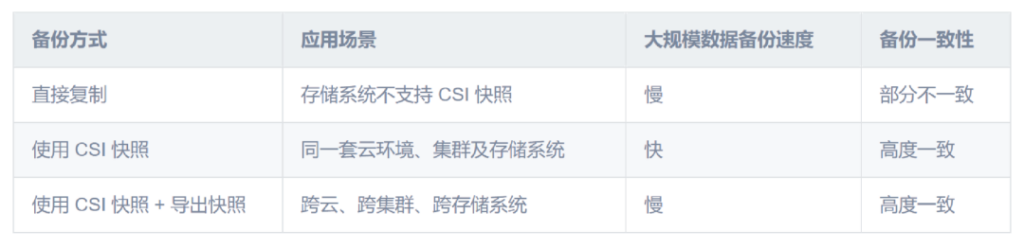
通过定时备份、恢复,时刻保障应用的生产安全。场景基础且核心,有效避免因为遭受恶意攻击或故障而导致的停机。通过增加备份细粒度,及时挽回业务数据。目前有两种实现方式:
方式1:基于存储的本地快照
支持 CSI 快照接口,把需要备份的 PVC 数据保存在当前的卷下,然后与 API 相关的原数据将传输到 S3 对象存储。这种基于 CSI 的快照,能够更好地保护应用的数据一致性。基于导出的快照可快速迁移恢复到另一个目标集群,恢复应用响应。
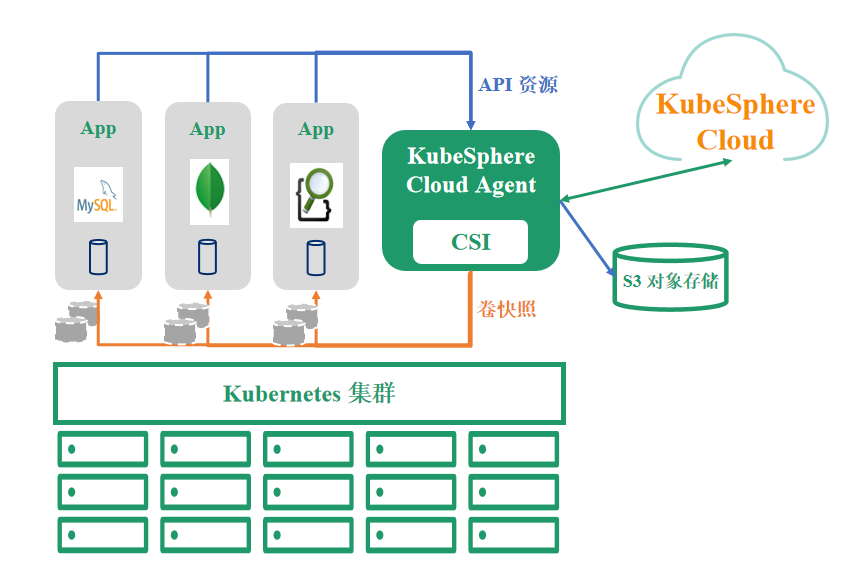
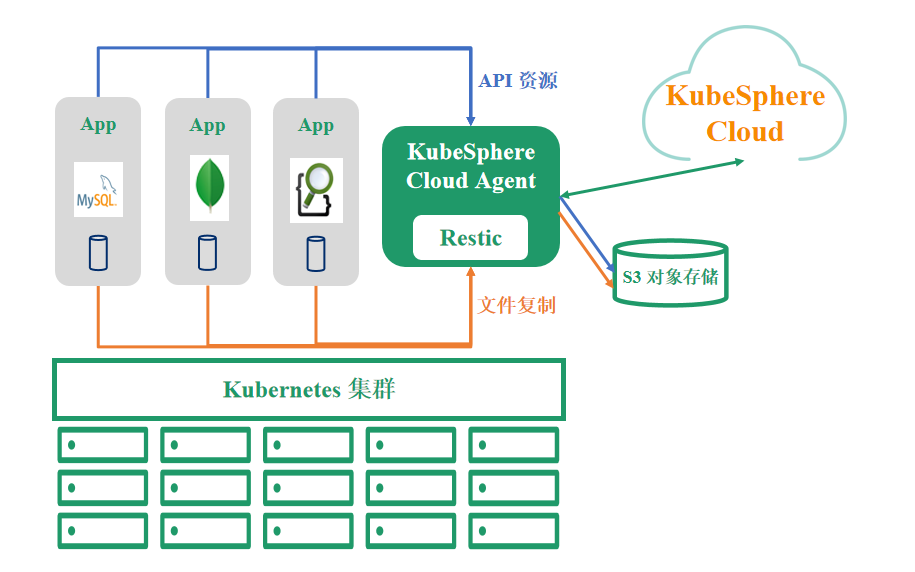
方式2:基于 Restic 的文件复制
这种方式是以文件复制的形式来进行的。如果集群存储不能够支持相关的存储接口,那么将对应的 API 资源和 PVC 数据备份到相应的 S3 对象存储中,将 S3 对象存储复制到目标集群,然后将应用恢复起来。这种方式在自身数据一致性、同步时间、性能等方面会稍微差一些。
场景二:基础设施变动
无论是伴随着公共云上面的资源迁移,还是实现多集群多存储协同保护,其实都在实现降本增效。
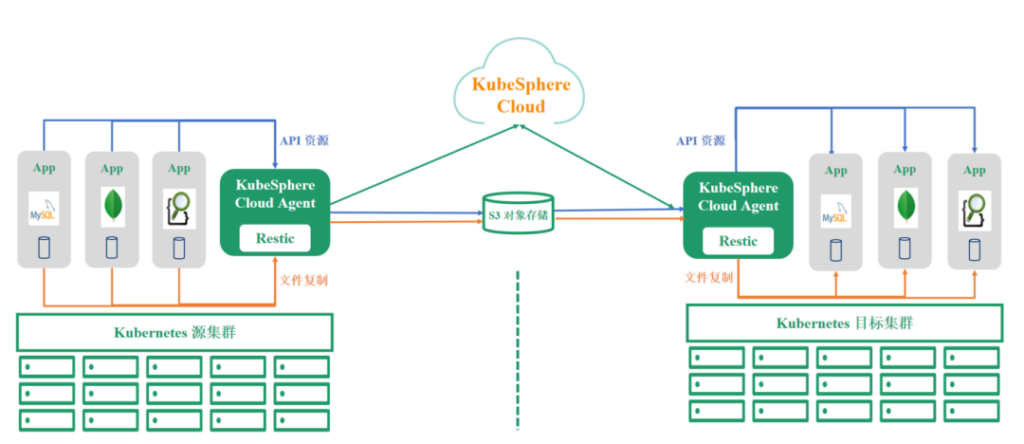
云迁移方案,针对于跨 Kubernetes 集群的方案,在更换云基础设施场景常见。比如,此时有更适合的云厂商资源,需要将资源迁移过去。先在目标云资源中启用一套 Kubernetes 集群,然后逐步把源端的 Kubernetes 应用迁移到目标端应用上,逐步验证新集群应用是否有效。由于目前 Kubernetes 升级迭代速度较快,迁移过程可能会出现一些问题,比如:不同版本 Kubernetes 的 API 兼容程度,应用适配等。
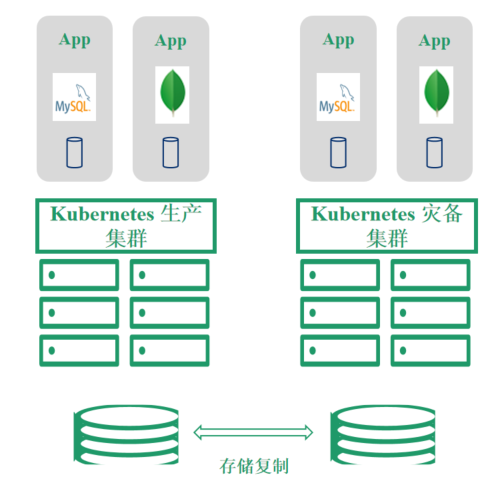
场景三:保障业务连续性
云容灾相对传统容灾方式,能更好保障服务高可用和业务连续性。
就像对一个 Kubernetes 的生产集群灾备,需要在远端准备一个跟当前集群基础设施存储一模一样的集群用于灾备。然后通过日常的增量复制,将增量数据时刻恢复到灾备站点中。如果生产集群挂掉了,我们可以及时的启用灾备集群。
这种方式的 RPO 和 RTO 非常好,但是代价也非常高,需要一整套相同的灾备集群基础设施,而且灾备站点日常不能跑其他的工作负载,恢复概率很高。
这种方式下的 Kubernetes API 资源也是增量备份在 S3 对象存储。如果生产环境挂掉,可以直接从 S3 存储中获取快照和元数据,将它们快速恢复到一个集群环境。这种方式对基础设施没有太多要求,是支持异构的,但 RPO 和 RTO 就存在一定局限性,对恢复效率带来一定的影响。
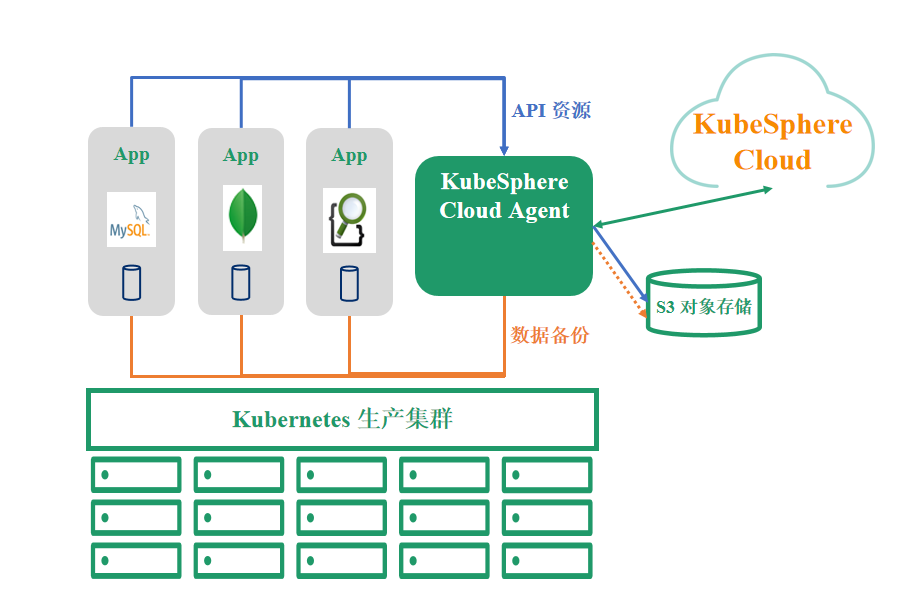
更健壮、易用、高效的企业级云原生备份容灾
KubeSphereCloud 提供的云原生备份容灾是一款 SaaS 服务,通过云端托管部署的方式,来管理云原生数据保护组件。针对不同客户场景,提供私有化集群部署的解决方案,以确保对数据的掌控能力。云原生备份容灾服务有如下显著产品特性:
特征1:应用级数据库保护
以应用为最小颗粒度,基于应用构建端到端备份容灾。应用的各种配置信息、PVC 数据等在任务执行中都能得以有效保护。
特征2:核心业务保障
支持基于 CSI 的存储快照备份与快照导出,有效保护 MySQL、MongoDB、Redis 等有状态应用的数据一致性,保障关键应用的异地恢复和跨站点高可用。
特征3:跨云容灾备份
屏蔽了技术堆栈带来的差异性,支持对跨云、跨可用区、跨 Kubernetes 版本的集群进行容灾备份,为企业不同的容器应用提供了安全、统一的保护方案,无厂商锁定。
特征4:直观易用的管理界面
用户无需掌握 Kubernetes 备份的专业知识、工具,几步操作即可轻松执行数据保护任务。相较 Velero 等开源应用,极大程度降低了使用难度。
下面我们根据几个具体的实践案例来展示服务特性。
实践一:保障有状态应用的数据一致性
CNCF 的调查报告显示,有状态应用容器部署的比例非常高,达到 55%。典型的有状态应用主要包括:消息系统、数据库等,属于需要应用数据保护的范畴。
如今一个显著的事实是,数据库应用逐渐走向 Kubernetes,优势:
- 数据库的安装、配置和维护更简单
- 跨云的部署兼容性更好
- 数据库和应用在一个平台上运维,无需分开部署运维
- 快速部署数据库实例
容灾备份服务可以更好的发挥本地快照的性能优势,满足 CSI 一致性要求,秒级创建快照,减少对数据一致性对应用业务的影响。
还可以在执行备份容灾操作前后,根据客户有状态应用的 I/O 情况、企业服务时间、运维周期等维度等条件,通过配置 Hook 策略执行操作,避免因为备份恢复对企业业务造成影响。配合本地快照更快更好的保护有状态应用的数据一致性。
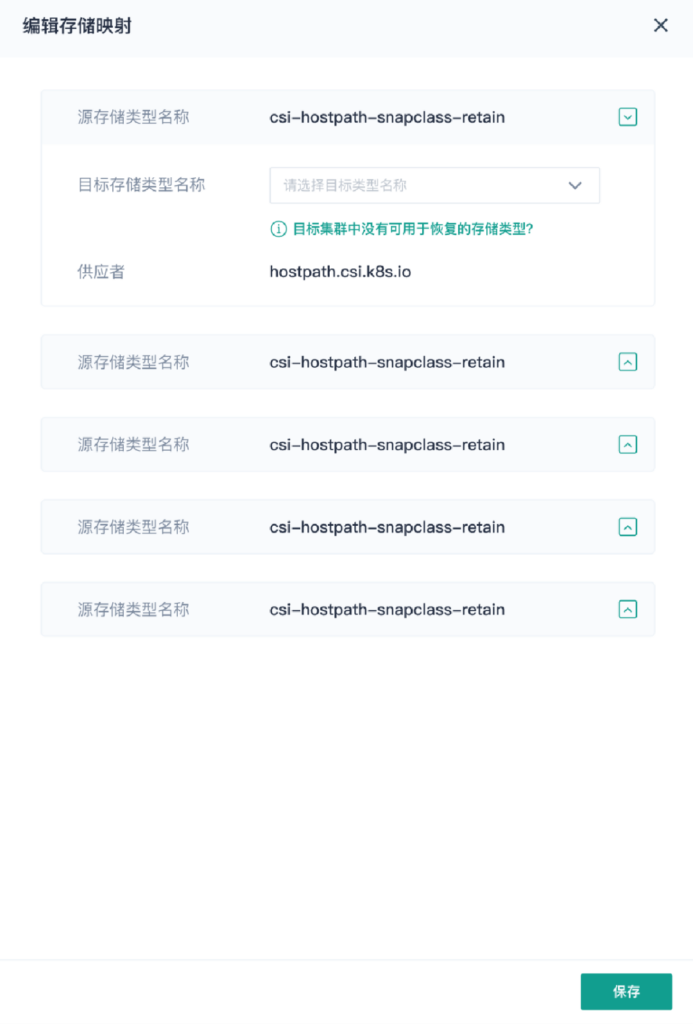
实践二:满足跨云跨集群的应用迁移
在 Hook 程序和本地快照方式的加持下,可以很快打包创建 CSI 快照,然后通过手动将快照导出,导入到目标的 S3 存储上并恢复到目标 Kubernetes 集群。
当两端 Kubernetes 集群的 StorageClass 不一致,可以通过在服务中配置两端存储卷映射关系,使得导出后的快照能够顺利导入到目标集群,实现应用迁移。该功能支持的非常完善。
实践三:满足复杂的备份容灾选择粒度需求
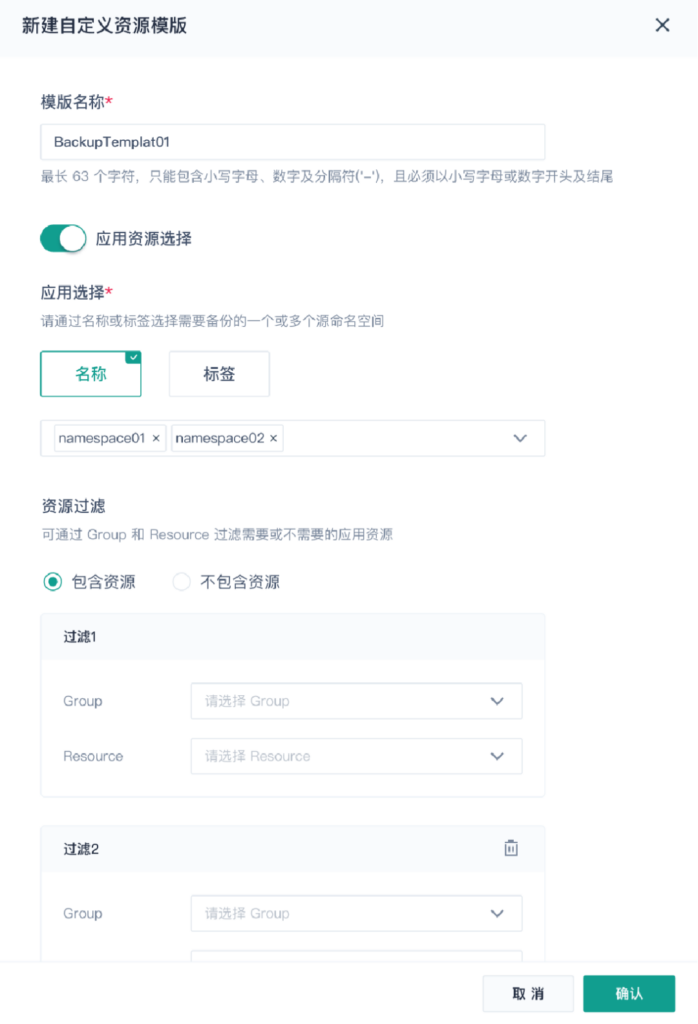
往往在应用备份粒度上有不同需求,比如 DevOps 用户备份时可能同时依赖几个 NameSpace 或 Cluster 资源,很大的工作负载和常见应用备份怎么实现呢?
1、多 NameSpace 的选择
可以通过 NameSpace 的 Name 或者 Label 两个维度,进行可视化的 NameSpace 筛选,并可一次性选中并备份多个 NameSpace。
2、应用负载资源的过滤筛选
直接定位到 NameSpace 可能会产生一些冗余备份,如果直接定位到工作负载这个级别,一个 Filter 中,可通过 Group/ Resource / Version / Name 等维度选择或排除备份的资源。还可以创建多个 Filter,实现应用的灵活管理。
3、Cluster-Level 资源的选择
在新集群启用时,需要依赖一些 Cluster-Level 资源,可以对这些资源进行单独的备份,从而实现更加细粒度资源的选择。
和开源的备份恢复工具 Velero 相比,KubeSphere Cloud 提供的云原生备份容灾服务有诸多关键的附加价值。
- 充分测试验证,安心、可靠
- 企业级测试验证
- 安全事故极大先于社区处理
- 7*24 全天候省心支持
- 补充更多企业级功能
- 多集群纳管
- 跨云迁移与云容灾
- 有状态应用一致性保证
- 快照导出与存储映射
- 强大的备份资源模板
- 更加直观易用
- 中文向导式界面
- 完整清晰的产品文档
- 高效的安装部署过程
- 良好支持国产化环境
- 国内主流公有云厂商支持
- 国内主流 Kubernetes 平台支持
- 国内主流存储厂商支持
备份容灾用户权益
目前该服务已经上线到 KubeSphere Cloud 网站,会长期提供一个免费的版本,即 100GB 免费托管存储容量。
我们将保持中立开放的态度,不限制用户基础资源类型、仓库类型等。提供相应的应用保护数和托管存储容量,方便个人用户测试体验,去支持数据备份迁移的场景。
扫描下方二维码,进群即可沟通、体验
